K-Tensors – Clustering Positive Semi-Definite Matrices
Functional Connectivity Matrix
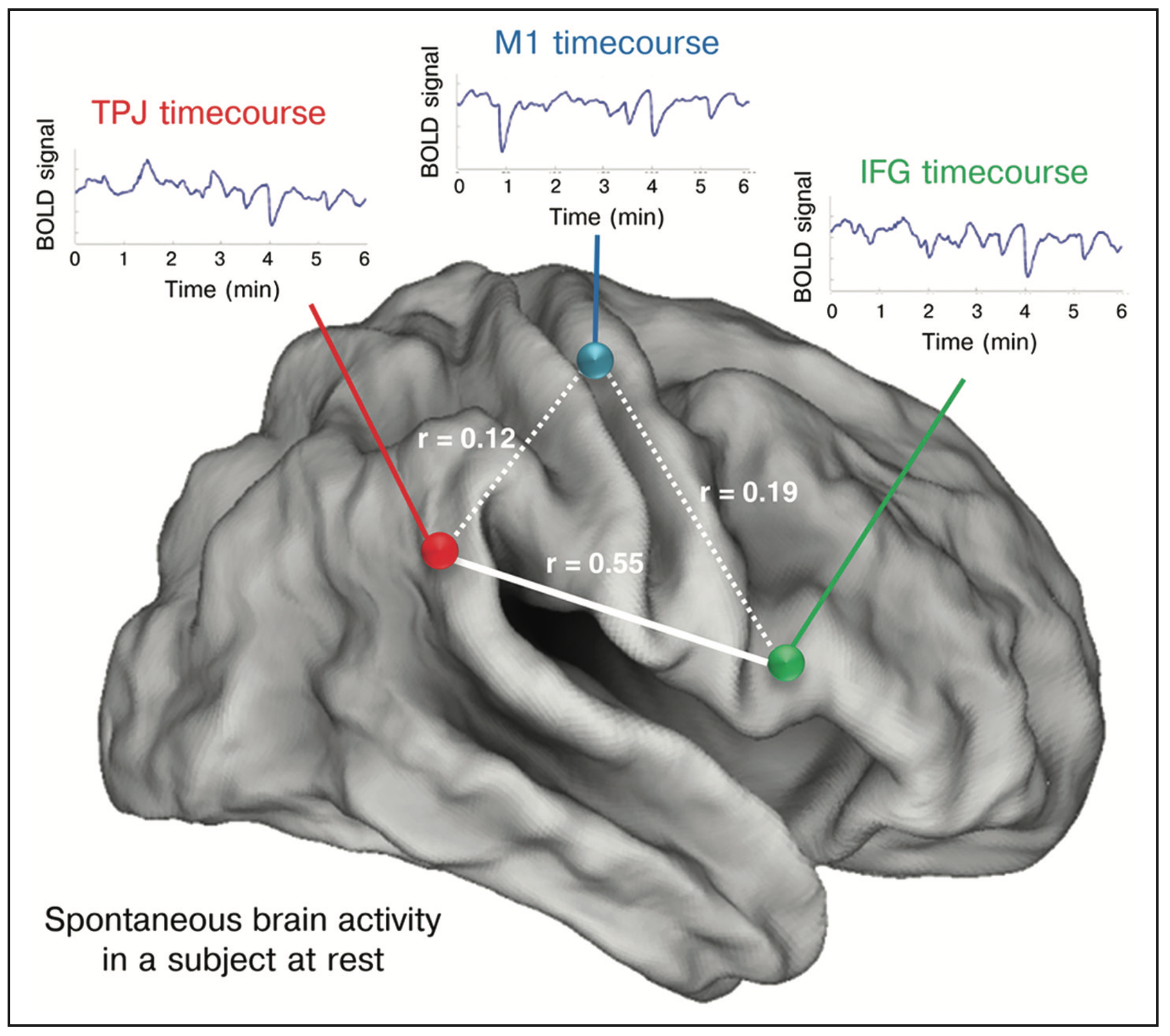
Functional Connectivity. [Gillebert et al., 2013]
Functional connectivity is defined as the temporal coincidence of spatially distant neurophysiological events.
For each participant \(i\), let \(\mathbf{y}_{ij} \in \mathbb{R}^{\mathscr T}\) be the longitudinal measurement of blood oxygen level-dependent (BOLD) signal on the region of interest \(j\), \(j = 1,2,\ldots,p\).
The functional connectivity matrix for participant \(i\) is the covariance matrix of \(\mathbf y_{i}\): \(\mathbf{\Sigma}_i = \textbf{Cov}(\mathbf{y}_i) \succeq \mathbf{0}\)
We want to link the functional connectivity matrix to the clinical outcomes using clustering methods.
More on K-Tensors

